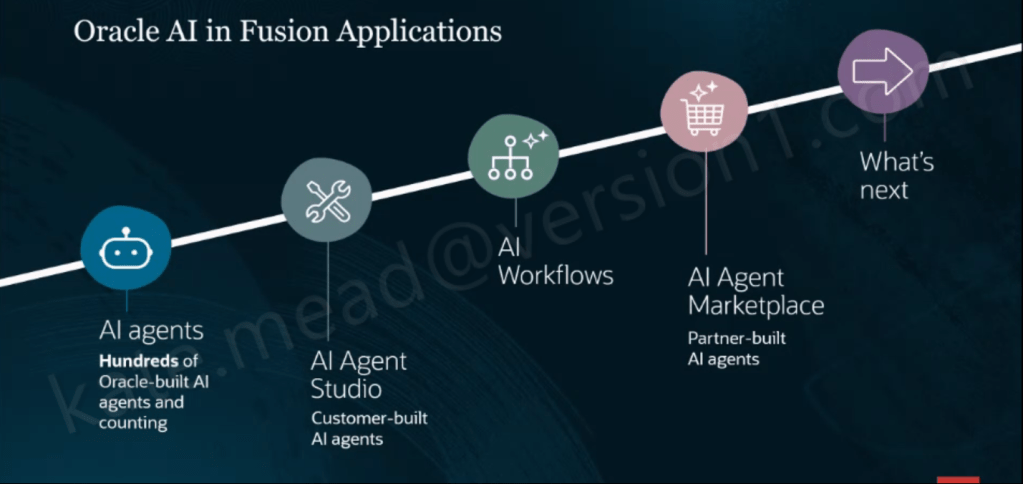
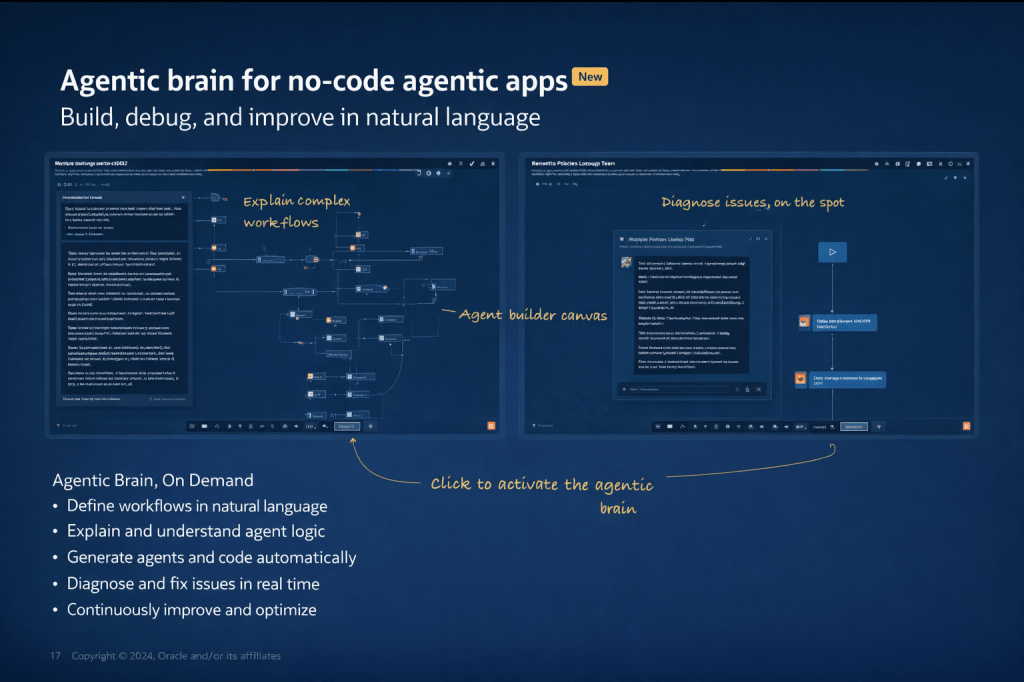
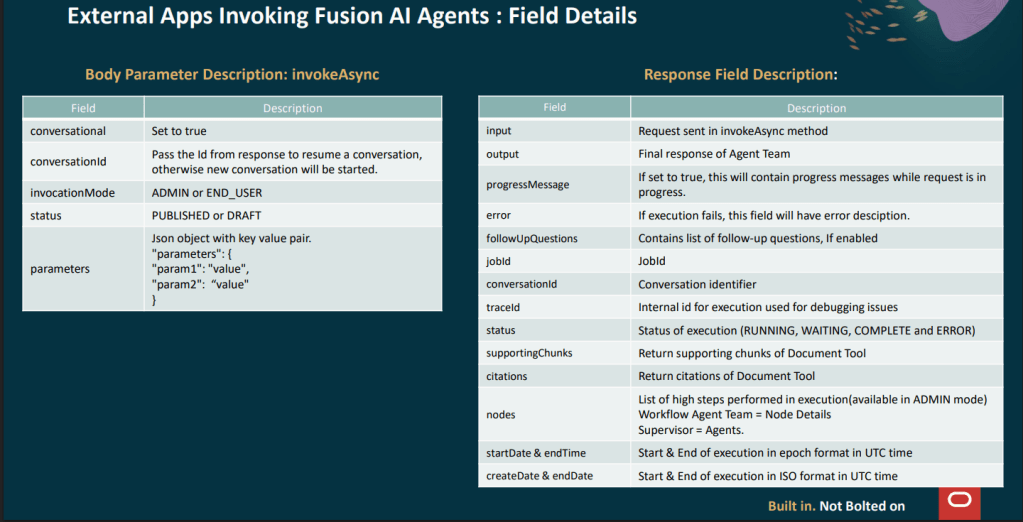
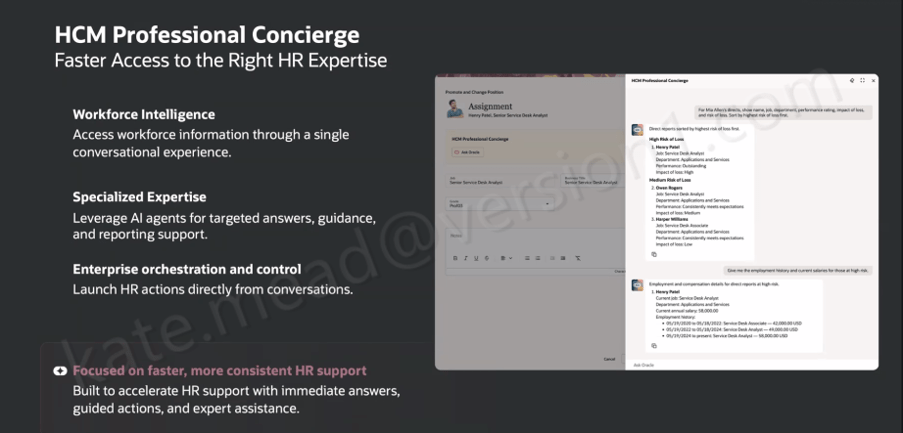
Oracle has been steadily building out its AI story in HCM Cloud, but the HCM Professional Concierge is one of the first examples that really feels tangible for HR teams. This is not AI added for the sake of it. It is a set of purpose-built, role-aware conversational agents, built directly into the HCM Redwood experience. For me, it stands out as one of the more considered uses of AI Agents in enterprise HR.
If you work in HR operations or as an HR Business Partner, the scenario will feel familiar. A manager wants to understand where their team sits on compensation ahead of a salary review. They open Employment Info, scroll through individual records, try to piece together performance data from one place, compensation history from another, and absence data from somewhere else. It is not a difficult task, but it is a fragmented one. Before long, ten minutes have passed just getting a basic view.
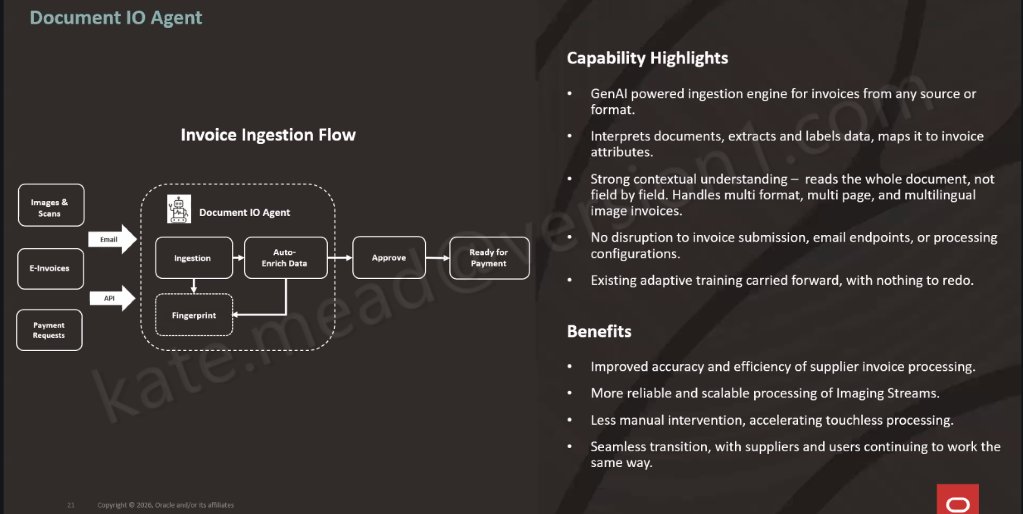
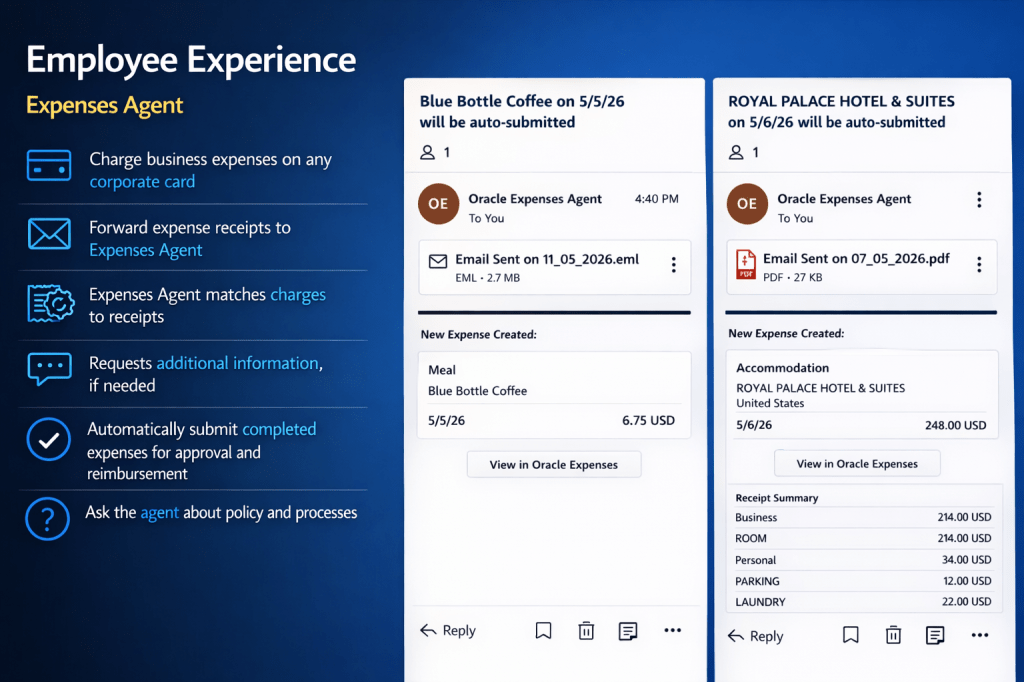
The HCM Professional Concierge simplifies this by bringing everything into a single conversational experience, embedded wherever the HR user is already working. Instead of navigating between screens, they ask a question. The agent brings together the relevant data, guides the next step, and in some cases can even trigger the action directly from the conversation.
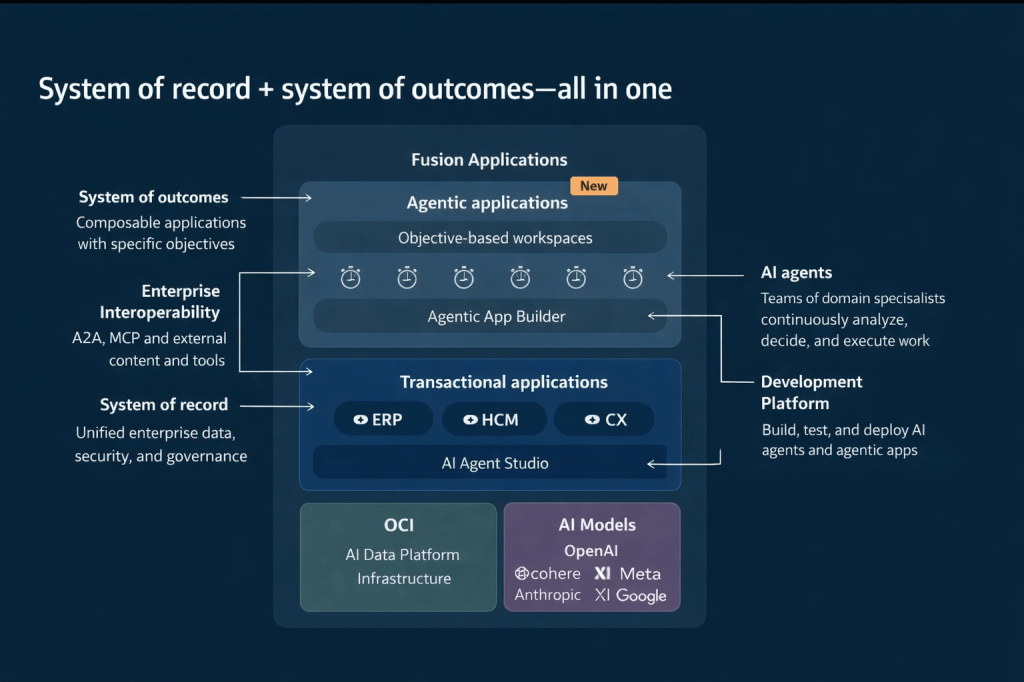
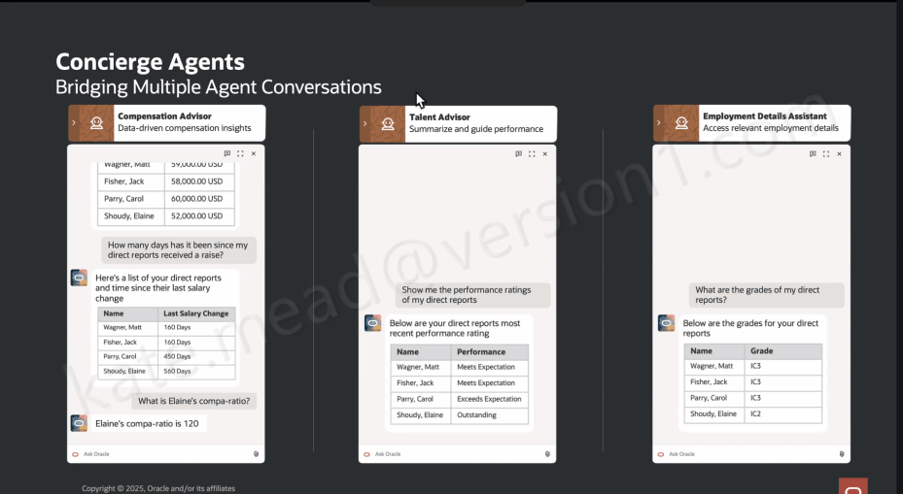
It is worth understanding that this is not a single AI agent working behind the scenes. Oracle has taken a supervisor and sub-agent approach, where a top-level Concierge Supervisor receives the user’s query, interprets the intent, and then routes it to the most appropriate specialist agent.
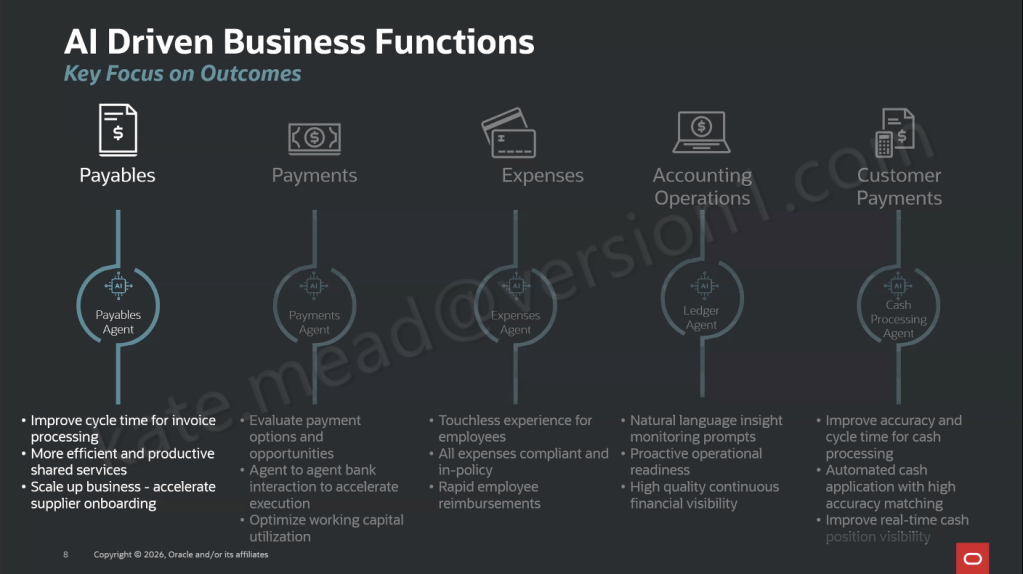
Within the HR Professional Concierge, those specialist agents each focus on a particular area of HR. For example, the Compensation Advisor brings together key information such as compensation data, compa‑ratios, time since the last salary change, and pay grade details for a manager’s direct reports. The Talent Advisor focuses on performance, helping to summarise ratings and support more informed performance conversations.
Other agents support core HR data and processes. The Employment Details Assistant provides access to employment history, assignment information and worker details, while the Leave and Absence Analyst helps identify and manage absence across a team. There is also support for understanding organisational design through the Workforce Structures agent.
In addition, the Concierge can surface policy and guidance through the Policy sub-agent, review personal worker data where needed, and launch reporting through the Reports sub-agent. For broader, team-level insight, the Team Data Hub helps bring data together to support analysis.
What this means in practice is that the user experiences a single, coherent conversation, even though multiple specialist agents may be working in the background to fulfil the request.

So when a manager asks, “show me the most recent performance rating and time since the last salary change for my direct reports”, the Manager Concierge Supervisor recognises that the query spans both compensation and talent data. It then coordinates across the Compensation Advisor and the Talent Advisor behind the scenes. What comes back is a single, joined-up view, rather than two separate outputs that the manager has to reconcile themselves.
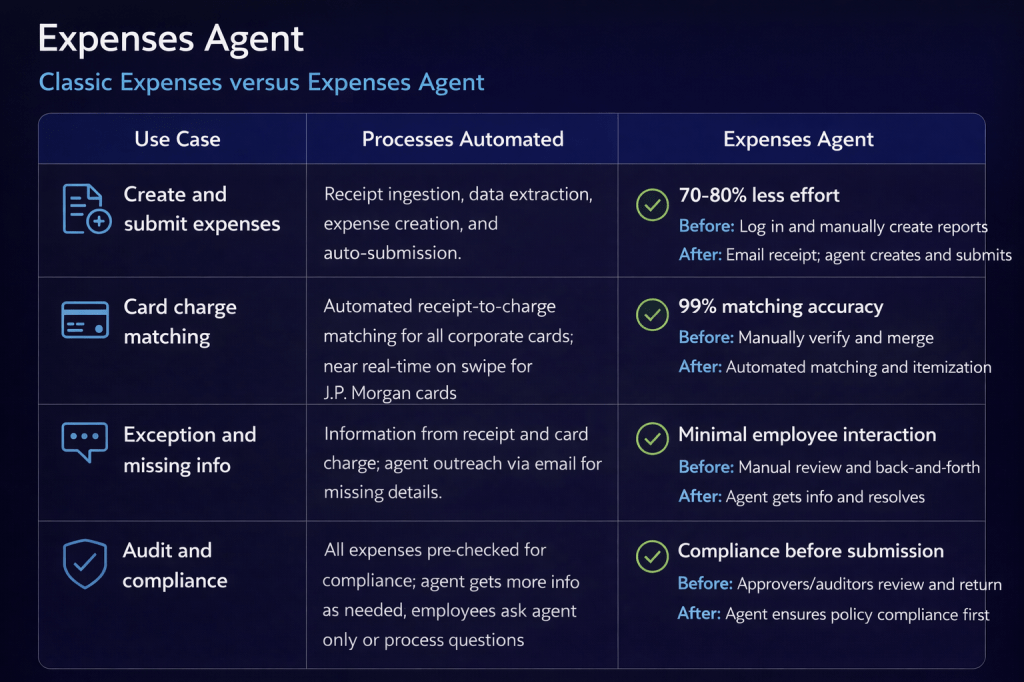
That orchestration across multiple agents is where the real value starts to show. Conversational assistants in enterprise applications are not new in themselves. What is more interesting here is the ability to coordinate specialist agents within a single interaction, carry context across the conversation, and route requests intelligently based on both the topic and the data required.
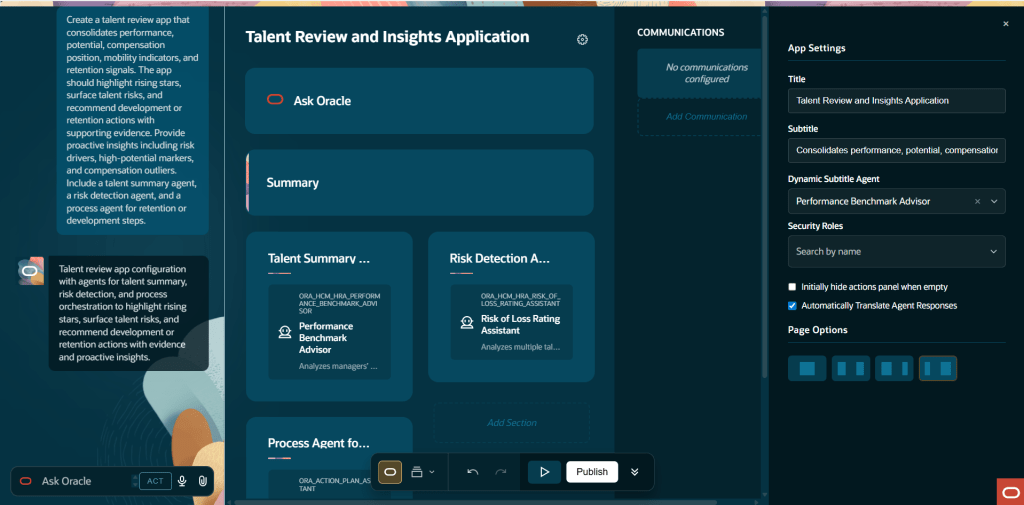
Oracle has introduced three distinct Concierge experiences, each designed around a specific user group and how they typically work. The HCM Professional Concierge is aimed at HR specialists and HR Business Partners. It sits within the HCM Professional Activity Centre, which has become the central workspace for HR service delivery, and supports the sort of queries an HR analyst would usually run. That includes pulling together workforce data for individuals or manager populations, reviewing compensation and employment history, running reports, looking up policies, and guiding HR actions within the flow of work.
The Manager Concierge is focused on line managers who need quick, straightforward access to information about their teams. It brings together compensation, absence, talent and employment data without the need to navigate into individual worker records. The experience adapts based on both the question being asked and the context of the manager’s team, giving them a practical way to not only view information but also complete common HR tasks directly.
The Worker Concierge, meanwhile, is designed for employees themselves. It brings together support for areas such as leave, payroll, benefits and compensation into a single, consistent experience. Behind the scenes, it routes queries to the relevant specialist agent, whether that relates to absence, benefits, pay, or compensation, so the employee does not need to think about where to go to get the answer.

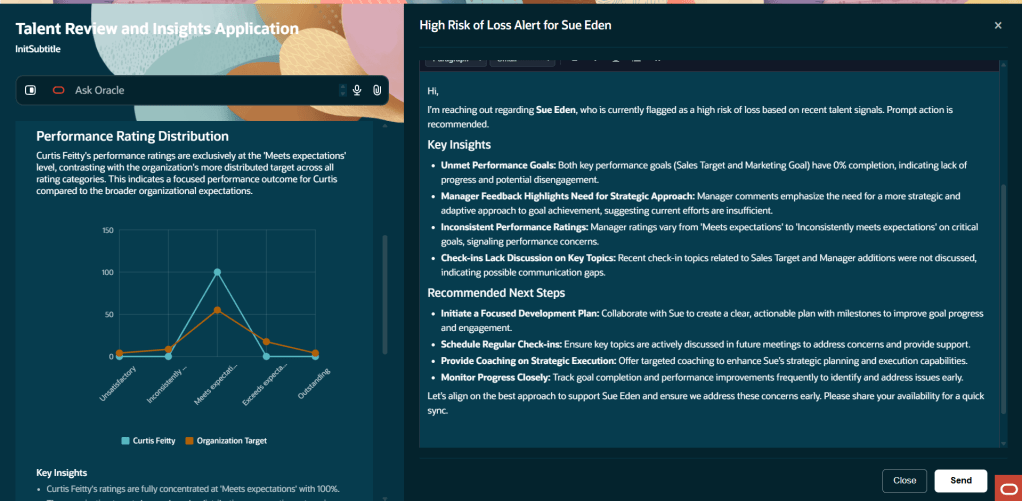
A simple scenario helps bring this to life. A line manager has been told that budget has been allocated for pay rises and promotions across the organisation. Before making any decisions, she wants a clear view of where her team currently stands. Using the Manager Concierge, she can ask a straightforward question in natural language, such as “how long has it been since my direct reports received a pay rise?” The Compensation Advisor returns the answer in a structured, easy-to-read format. She then follows up with a more specific question, “what is Elaine’s compa-ratio?”, and gets a direct response.
Within the same conversation, she can ask for performance ratings through the Talent Advisor and pull through grade information using the Employment Details Assistant. It all happens in one place, without needing to navigate between screens. Multiple specialist agents are working in the background, but from the manager’s perspective it feels like a single, joined-up interaction.
The HR specialist perspective is just as telling. If someone is working on an Employment Info page for a specific worker, they can open the Concierge panel and ask something like, “what is the salary history for Ravi?” or “where is Ravi located?” The response comes back as structured data pulled directly from HCM, without the need to navigate away or open multiple pages.
One question that comes up consistently when Oracle’s AI features are discussed is around data access and security. It is an important one, and the answer here is reassuring. The HCM Professional Concierge works within the same data and functional security model already applied across the HCM Redwood experience. If an HR specialist does not have permission to view a particular employee’s salary in the core application, they will not be able to access it through the Concierge either. There is no separate access layer being introduced. It simply operates within the role-based controls that are already in place.
For organisations working across multiple geographies, the same principle applies. The agent respects the existing configuration of Redwood pages, including any geography-specific policies and legislative requirements. There is also flexibility to tailor how the agent behaves by refining prompts to reflect your organisation’s terminology or local nuances.
The Concierge also sits within a broader shift in how Oracle is shaping the HR user experience. It is alongside the HCM Professional Activity Centre, which acts as a unified Redwood workspace for HR administration. The Activity Centre brings together a more flexible approach to worker search, with filtering, saved views and personalised results. From there, HR specialists can move straight into transactions from a worker’s profile without switching to a separate area. Common actions are surfaced directly in the interface, including access to areas such as the Recruiting Activity Centre, Mass Assignment Change, Mass Legal Employer Change, Payroll Activity Centre and Attendance Violations, which makes it easier to act on information as soon as it is identified.
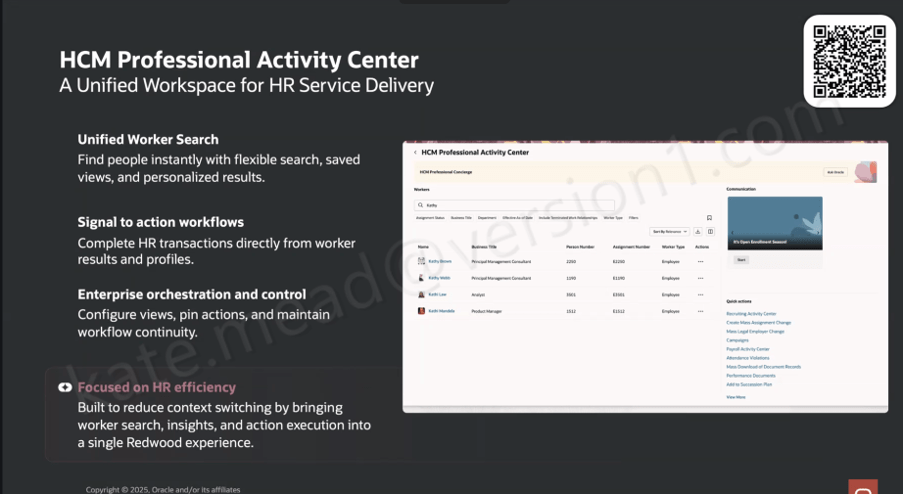
The Concierge is always present within the Activity Center, giving HR specialists access to conversational support in the context of the work they are already doing.
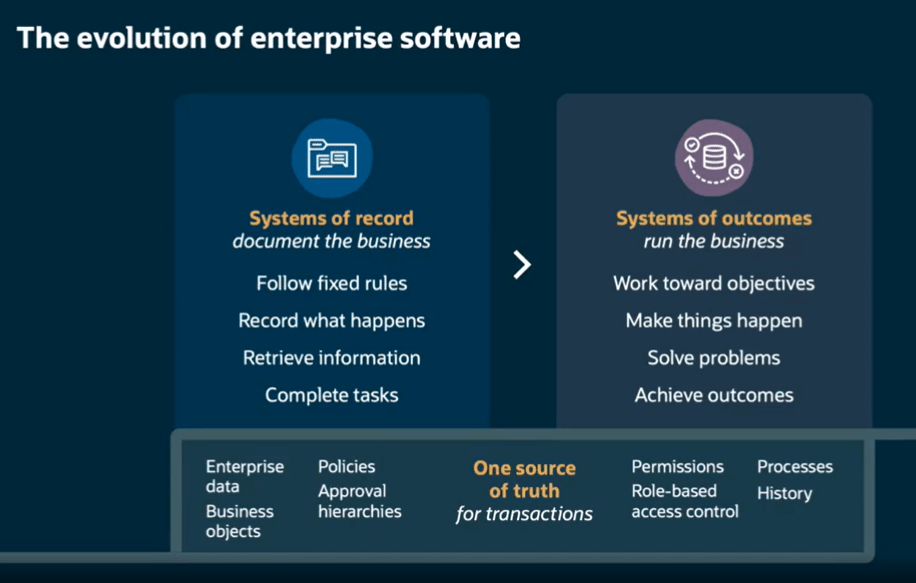
It also sits within a much broader direction Oracle is taking with role-based, agent-led HR applications. The HR Specialist Workspace is a good example of where this is heading. It builds on the same foundations, but moves towards a Redwood workspace where multiple specialist agents work together to surface relevant insights more proactively.

In that model, the workspace brings together a view of workforce priorities, potential restructuring impacts, compliance alerts, attrition risk and open HR cases. These are drawn from coordinated agent outputs across areas such as Workforce Management, Talent and Learning. The shift here is subtle but important. The agents are not just responding to questions, they are actively identifying what might need attention and presenting it to the user.
There is also a clear emphasis on governance. Audit trails, controls and human oversight are built into how actions are handed off. Oracle is quite deliberate in positioning this around measurable outcomes, with coordinated agent activity and clear decision points. That creates an important distinction from more autonomous AI models. Here, the agents surface and recommend, but people remain firmly in control of decisions and actions.
From an implementation perspective, the HCM Professional Concierge and its supporting agents are delivered as part of Oracle HCM Cloud Release 26C. There is no need to build these capabilities from the ground up. They are available out of the box, with the ability to adapt behaviour through prompt configuration so that it reflects your organisation’s terminology and ways of working.
As ever, I will keep a close eye on how this develops across the HCM suite and share updates as new capabilities emerge. If you are starting to think about how this fits into your wider HCM AI strategy, or you are planning for a 26C upgrade, now is a sensible point to begin that conversation.
Please note all screenshots are the property of Oracle and are used according to their Copyright Guidelines