Oracle has introduced a significant enhancement to data extraction in Fusion Cloud Applications with the Read-Optimised Data Store (RODS) and the new Data Extraction Tool. Together, these capabilities provide a modern approach to accessing Fusion data for reporting, analytics and integration workloads, without placing additional demand on live transactional systems.
For organisations looking to feed data warehouses, support operational reporting or enable near real-time integrations, this represents an important shift in how Fusion data can be accessed and consumed.
Traditionally, organisations have relied on a combination of BICC (Business Intelligence Cloud Connector), REST APIs and BI Publisher (BIP) reports to extract data from Fusion. Each approach has advantages, but also limitations. BICC provides reliable bulk extracts, although these are batch-based by design. REST APIs can deliver more current information but often require significant orchestration and development effort. BI Publisher allows flexible data extraction, but queries execute against the same database that supports day-to-day business transactions.
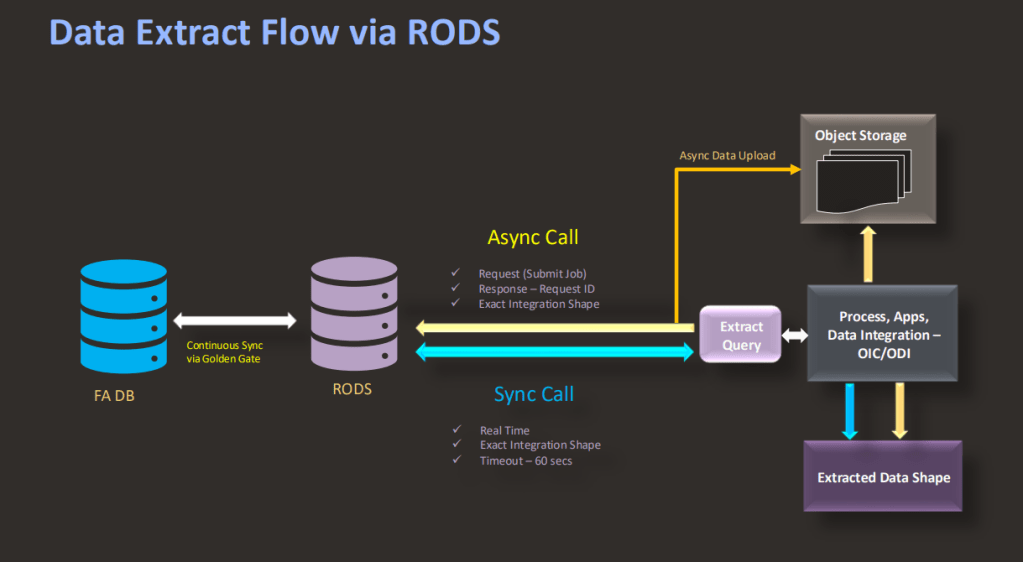
RODS addresses these challenges by separating data extraction from transactional processing. Rather than querying the live application database, extracts run against a dedicated read-optimised environment that is continuously synchronised with Fusion Cloud. This allows large-scale data extraction activities to take place without competing for resources with business operations.
RODS, or Read-Optimised Data Store, is built on Oracle Autonomous AI Lakehouse technology and is designed specifically for high-volume, read-intensive workloads. Fusion data is continuously replicated into RODS using Oracle GoldenGate technology, providing a near real-time representation of transactional data. The result is a platform that supports reporting, analytics and extraction activities without impacting application performance.
Importantly, Oracle is deploying RODS to customers through its Oracle Application Platform technology upgrade programme. There is no separate infrastructure to purchase or manage, and customers can request early enablement through Oracle Support where available.
The Data Extraction Tool provides a modern, Redwood-based interface for creating and managing data extracts.
Available from release 26A onwards, the tool enables users to define extracts through a straightforward configuration process rather than complex development work. To enable the functionality, organisations must activate the feature in Setup Manager under the Manufacturing and Supply Chain Materials Management offering. Oracle Support must also complete the backend activation, and the appropriate security roles must be assigned before users can access the application.
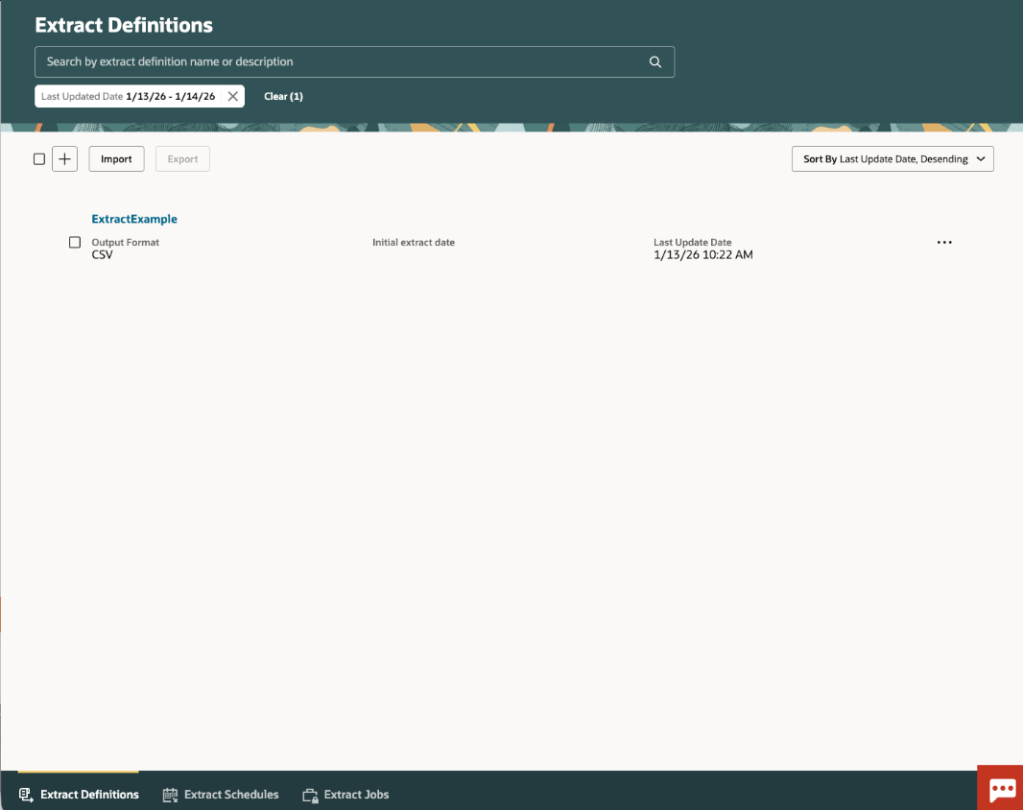
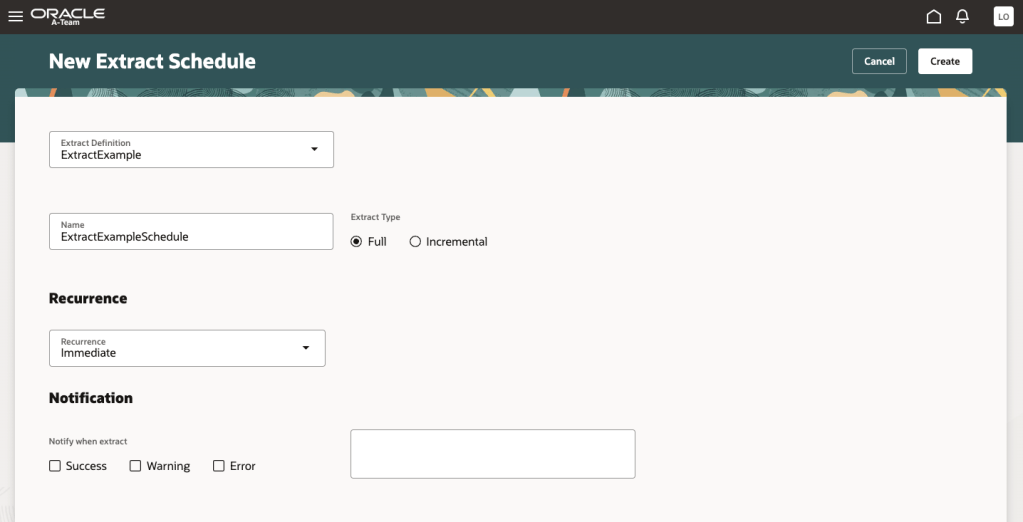
Once enabled, the Data Extraction Tool can be accessed from the Tools menu and is organised around three key areas. Extract Definitions allow users to create and maintain data extraction configurations, selecting the business objects, fields and filters required. Extract Schedules provide a straightforward way to automate the execution of extracts at regular intervals, while Extract Jobs offers visibility of running and completed extractions, making it easy to monitor progress, review results and investigate any issues.
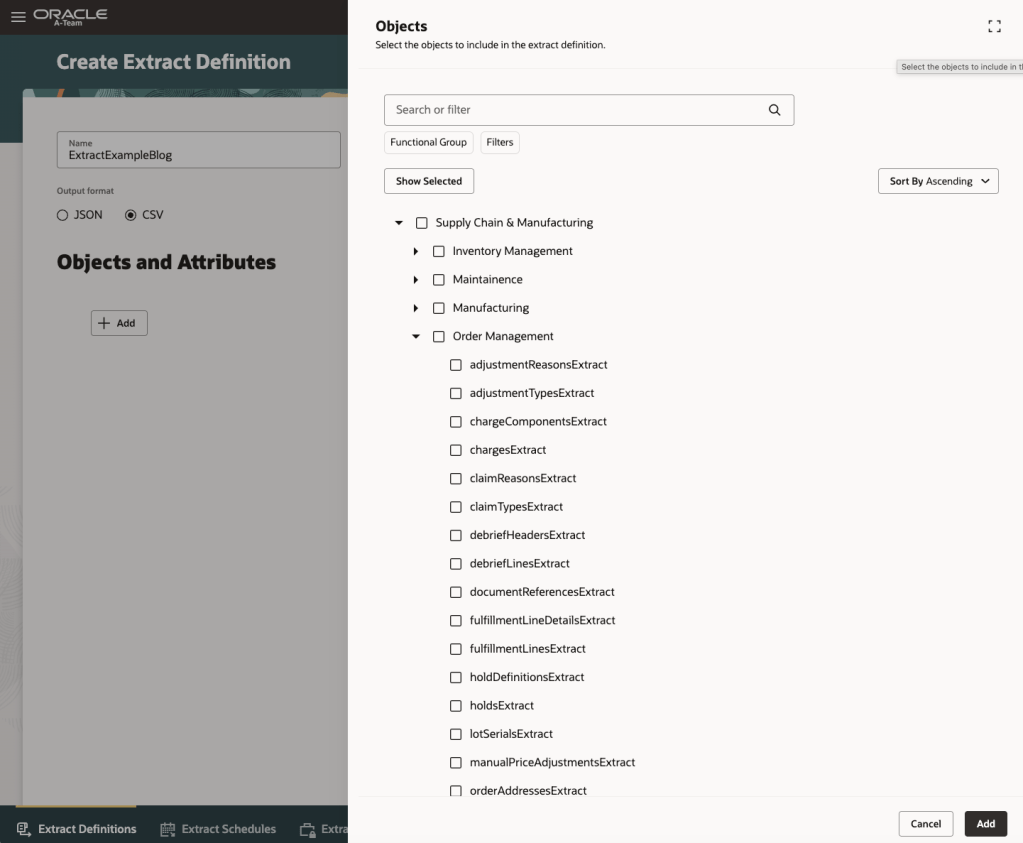
Creating an extract is largely a point-and-click process. Users define an extract name, select an output format (CSV or JSON), choose the required business objects, and specify the fields they wish to include. Filters can be applied to narrow the data set, while column names can be renamed to match downstream integration or reporting requirements.
The tool also supports both Descriptive Flexfields (DFFs) and Extensible Flexfields (EFFs), allowing organisations to include custom attributes alongside standard Fusion data. Extract definitions can be saved for reuse, executed on demand, scheduled for regular execution, or exported between environments.
The Data Extraction Tool supports two execution models:
Synchronous processing is intended for smaller data requests that can be completed immediately. Results are returned within the same transaction, making this suitable for focused data retrieval scenarios. Oracle currently applies a 60-second execution limit.
Asynchronous processing is designed for larger extraction workloads. Users submit a job and receive a job reference that can be used to monitor progress. Once complete, output files are delivered to Oracle Cloud Object Storage or UCM.
Each extract includes metadata detailing the extraction period, row counts and any processing errors, helping administrators validate results and troubleshoot issues.
One of the more interesting additions is Oracle’s Data Extraction Query Transformer Agent. Many organisations have invested heavily in BI Publisher reports and custom SQL queries over the years. The Query Transformer Agent helps modernise these assets by converting SQL into Business Object Query Language (BQL), the format used by the Data Extraction Tool. The agent also validates converted queries against the target schema, helping users identify issues before execution. Oracle has also indicated that future releases will introduce SQL performance assessment capabilities to help organisations identify optimisation opportunities before migration.
RODS coverage continues to grow with each quarterly release. In release 26B, Oracle supports more than 1,100 business objects and has mapped over 600 BICC public view objects. Release 26C is expected to increase coverage to more than 1,650 business objects and nearly 900 mapped BICC view objects, extending support across ERP, HCM, SCM and CX.
Organisations should be aware that business object attribute names may not always match existing ADF View Object or BICC naming conventions. However, output column names can be customised, providing flexibility for downstream integrations and reporting solutions.

Release 26D is set to introduce several important enhancements, including support for custom queries across both synchronous and asynchronous extractions, as well as callback capabilities that enable event-driven processing and notifications.
Oracle is also investing in additional self-service capabilities, including richer extract management, reusable query registration, pre-execution testing and AI-assisted query analysis. As these capabilities mature, the Data Extraction Tool is increasingly positioned as Oracle’s strategic approach to data extraction from Fusion Cloud Applications.

For organisations that currently rely on BI Publisher for integration-focused data extraction, or those finding limitations in existing BICC-based approaches, RODS is worth evaluating. By separating extraction workloads from transactional processing, Oracle has created a more scalable and modern foundation for reporting, analytics and integrations. While coverage is still expanding, the direction is clear: RODS and the Data Extraction Tool are becoming central to Oracle’s long-term strategy for accessing Fusion Cloud data.
Please note all screenshots are the property of Oracle and are used according to their Copyright Guidelines